


话题分析的相关方法
什么是话题
- 定义:一个文档或文档集合所描述的主题(topic);
- 表示:一个话题可以用一个关键词/关键短语/短句子描述;
- 类型:
- 用人物/动物、地名、组织表示。例如“大熊猫'成功'曾生育9只大熊猫”;
- 用事件表示,例如“青海西宁山洪已致16人死亡36人失踪”;
- 用标签表示,例如“疫情”;
话题分析的相关任务
实体识别
- 实体识别的英文术语为(NER)Named Entity Recognition,是指在一段文本中,将预先定义好的实体类型(人名,机构,地名等)识别出来。
- 例如,“2011年4月11日17点16分,日本东北部的福岛和茨城地区发生里氏7.0级强烈地震。”;
- 例如,“Dole ’s wife , Elizabeth , is a native of Salisbury , N.C.”;
- 实体识别的两个子任务:
- 实体边界识别(boundary detection)
- 确定实体类别(type determination)
- 面临的主要挑战:
- 实体包括人名、地名等,具有多样性;
- 实体的边界难以确定;
- 实体类型和任务、上下文密切相关;
序列标注的方法
- 进行NER时,通常需要对每个字进行标注,中文为单个字,而英文为一个单词。标注的标签类型如下表。
| 类型 | 说明 |
|---|---|
| B | Begin,代表实体片段的开始 |
| I | Intermediate,代表实体片段的中介 |
| M | Middle,代表实体片段的中间 |
| E | End,代表实体片段的结束 |
| S | Single,代表实体片段为单个字 |
| O | Other,代表字符不为任何实体 |
BIO
- BIO即Begin-Inside-Outside(含义参考上表),是一种三位序列标注法。
| 李 | 明 | 出 | 生 | 在 | 北 | 京 | 市 |
|---|---|---|---|---|---|---|---|
| B | I | O | O | O | B | I | I |
- 在BIO的基础上还可以加上对实体类型的描述,如
B-PER\I-PER\B-LOC\I-LOC\B-ORG\I-ORG......,'PER'指人名,'LOC'指地名,'ORG'指组织名,'MISC'指其他;
BIOES
- BIOES即Begin-Inside-Outside-End-Single,是对BIO的一个扩展。
| 李 | 明 | 出 | 生 | 在 | 北 | 京 | 市 |
|---|---|---|---|---|---|---|---|
| B | E | O | O | O | B | I | E |
BILOU
- BILOU即Begin-Inside-Last-Outside-Unit,其中的Last和End同义,Unit和Single同义。
话题跟踪
-
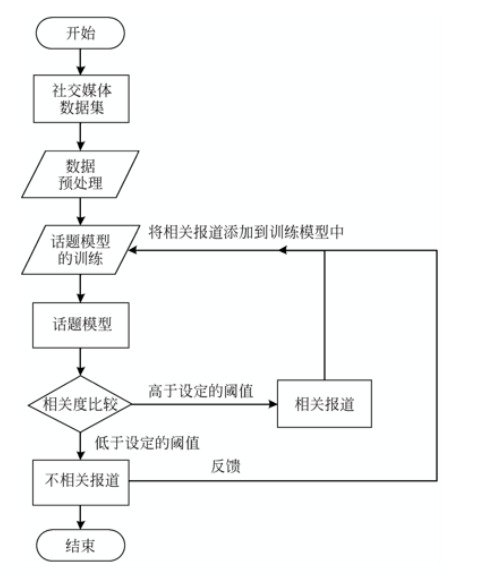
定义:给出某一话题的一组样本报道,通过训练得到话题跟踪模型,然后在后续报道中找出所有讨论目标话题的报道。
-
该任务的实质是通过有监督学习,训练一个二分类器,用来判别报道和话题的相关性。
-
有监督(supervised)是指输入数据含有标签,输入和输出有固定的对应关系;而无监督(unsupervised)是指输入数据无标签,需要从数据集中发现和总结。
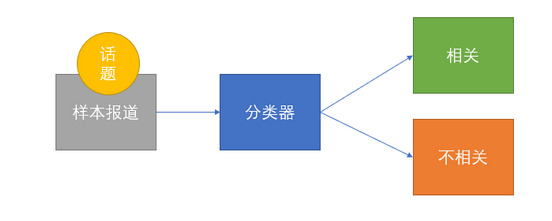
-
流程图如下:
向量空间模型
-
向量空间模型是最常用的检索模型,其方法是:每篇文档用一个向量来表达,通过向量空间的向量运算来表达语义的相似度。
-
基本概念
- 文档Document:泛指一般的文本或文本中的片段,这里对文本text和文档document不做区分;
- 项Term:是指文本的基本语言单位(字、词、短语等),这样一个文本就可以用项集(Term List)表示为
D(T1, T2, ..., Tn); - 项的权重TermWeight:对于含有n个项的文本D,项常常被赋予一定的权重表示在D中的重要程度;
- 向量空间模型VSM(Vector Space Model):为了简化分析不考虑语言单位出现的顺序,把文档D看成一个n维向量,n就是词库的大小;
- 相似度Similarity:就是指两个文本内容的相关程度(Degree of Relevance),我们可以借助向量之间的某种距离(内积\余弦值)来表达相似的概念;
-
每个文本向量的实际取值,不是简单的考虑某一项是否存在(存在填1,不存在填0),而是由该项的出现频率和权重决定。项在文档中出现的越多,说明该项更重要,同样地,不频繁出现的项,其权重应该比频繁出现的项权重更高。

-
VSM将每篇文档表示成一个基于tf-idf权重的实值向量。
-
tf-idf的权重:
- 随着项的频率的增大而增大(局部信息);
- 随着项的罕见度的增大而增大(全局信息);
-
问题是向量空间的维度极高,对于每个向量来说又十分稀疏,大部分的维度取值都为0;
上下文词表示
- 基本概念
- 窗口Window:即上下文的大小,窗口为1则上文只含一个词,下文只含一个词;
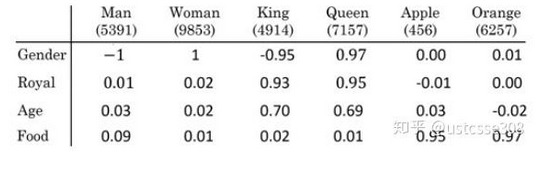
- 词向量Word Vector:词向量的构造方法叫做词嵌入word embedding,是将一个词X映射到另一个词汇空间Y(语料库corpus)。具体来说词向量就是一个
n*1维度的向量值。例如词向量X=(0.5, -1, 0.02, 0.08),X的每个维度取值是由给定的词汇空间计算得来的,X与该维度的词含义越相近,取值越趋近1,越相反取值越趋近-1。 - 下图就展示了将"Man", "Woman", "King", "Queen"等词语映射到(Gender, Royal, Age, Food)组成的词汇空间中,如
Man=(-1, 0.01, 0.03, 0.09);
Word2Vec
-
Word2Vec就是词嵌入的一种的算法,即如何在一个语料库中构造出词X的词向量
X=(v1, v2, ..., vn)。 -
Word2Vec的两种训练模式:
- CBOW:通过上下文来预测当前词;
- Skip-gram:通过当前词来预测上下文;
- 它们的具体训练流程参考word2vec详解(CBOW,skip-gram,负采样,分层Softmax);
Glove
- Glove也是一种词嵌入算法,和Word2Vec的目标相同,都是希望向量之间尽可能多地蕴含语义和语法的信息。具体训练过程参考GloVe详解;
一些工具
分类器
话题检测
- 该任务的目标是检测出未知话题以及相关报道;
- 实质是将某个话题所报道归入一个话题类,因此它是一个无监督的聚类问题。
k-means聚类算法
- 在机器学习中已经了解过k-means算法了,若不太记得可参考【机器学习】K-means(非常详细)
主题模型
- 主题模型(Topic Model)是自然语言处理中的一种常用模型,它用于从大量文档中自动提取主题信息。主题模型的核心思想是,每篇文档都可以看作是多个主题的混合,而每个主题则由一组词构成。
LSA
- 潜在语义分析LSA即Latent Semantic Analysis,通过奇异值分解(SVD)将文档-词矩阵降维,提取潜在的语义信息;
PLSA
- 概率潜在语义分析PLSA即Probabilistic Latent Semantic Analysis/Indexing,是一种基于概率图模型的方法,它将文档表示为主体的混合分布,主题表示为词的概率分布;
- 假定一共有K个可选的主题,有V个可选的词,我们可以把PLSA看成一个扔骰子的过程:
- 首先有一颗K面的“文档-主题”骰子,扔此骰子能得到K个主题中的任意一个;
- 另外还有K个V面的“主题-词” 骰子,且骰子的每一面对应要选择的词;

LDA
- 潜在狄利克雷分配LDA即LatentDirichlet Allocation,是一种生成概率模型,它在PLSA的基础上引入狄利克雷先验分布,它假设每篇文档由多个主题组成,每个主题由多个词组成。
- 其特点为:
- 是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系;
- LDA认为一篇文章往往有多个主题,只是这多个主题各自在文档中出现的概率大小不一样;
- LDA认为文档中每一个词都由其中的一个主题生成;
- LDA的训练过程可以看作文档生成的逆过程:根据给定的一篇文档,反推其主题分布;
事件抽取
-
事件抽取Event Extraction定义:从非结构化的文本中识别出特定类型事件的信息,然后将事件以结构化的形式表示出来。
-
基本概念:
- 以文本“到1920年12月,蒋介石与友人商议,决定改组公司,并且与商人张经初等人合作,成立恒泰号,以继续从事伤害证券物品交易所的经纪事业”为例:

- 事件描述Event Mention:描述事件信息的短语或句子,上述文本就是一个事件描述;
- 事件触发Event Trigger:标志某一事件发生的词语,一般是动词,上述文本中的“成立”就是“企业创办”事件的触发词;
- 事件元素Event Argument:用以描述一个事件的实践、地点、人物等重要信息,上述文本中的“1920年12月”、“蒋介石”等都是事件元素;
- 元素角色Argument Role:事件元素在事件进行过程中的作用,上述文本中的“1920年12月”描述了事件发生的时间,在“企业成立”事件中的角色是“成立的时间”;
- 以文本“到1920年12月,蒋介石与友人商议,决定改组公司,并且与商人张经初等人合作,成立恒泰号,以继续从事伤害证券物品交易所的经纪事业”为例:
-
任务:
- 从文本中发现命名实体(Named Entity),如苹果公司、乔布斯、美国;
- 触发词识别,从文本中发现事件触发词(Event Trigger),如发布会、竞选、会谈;
- 论元(角色)识别,判断实体在事件中扮演的角色,如组织机构、倡导人、发生地;
JMEE
- JMEE是一种事件提取的模型,具体参考【论文解读 EMNLP 2018 | JMEE】Jointly Multiple EE via Attention-based Graph Information Aggregation;
OneEE
To be updated......
Comments NOTHING